# 一、入门
# 1、kafka流式处理平台
# 1、作为流式平台需要具备3个特点
- 数据注入功能:类似消息系统,提供事件流的发布和订阅
- 数据存储功能:存储事件流数据的节点具有故障容错的特点
- 流处理功能:能够对实时的事件流进行流式地处理和分析
# 2、消息模型
- 队列模式(点对点模式):多个消费者读取消息队列,每条消息只会发送给一个消费者。即,同一个消费组的多个消费者,一个主题一条消息只给一个消费者去处理
- 发布订阅模式:多个消费者订阅主题,主题的每条消息会发布个所有的消费者。即,多个消费组,订阅一个主题,主题的每条消息广播给多个消费组
3、Kafka功能模块
- 消息系统,支持两种消息模型
- 存储系统
- 流处理系统,消息的读取和写入、存储消息流、实时的流式数据处理
- 将消息系统、消息存储、流处理组合,既可以实时处理消息,也可以处理过去的消息
# 2、kafka基本概念
# 1、分区模型
每种类型的消息视为一个主题
一个主题可以有多个分区(类似于分流、横向切分表)
每个分区的消费进度,采用偏移量来标记,即各个分区维护自己的偏移量
每个分区可以有多个备份(高可用)
每个分区在同一个消费组下的消费者内唯一,保证分区的消息在消费组内只会被消费一次,不会被多个消费者绑定从而导致重复消费的情况
分区结构类似于一个队列,队列的意义:有序、可存储。故,消息在分区内部是有序的。一个主题的分区之间是不能保证这个主题的消息是有序。
假如需要这个消息在整个消费组内有序:
- 通常情况下消息与消息之间是无状态的,可以采用流式处理的理念,把有状态的消息转换成无状态的消息,即一个主题消息经过处理发送到另一个主题,另一个主题消息时在写业务逻辑
- 如果硬要保证有序,也可以实现。可以将这个主题只设置一个分区,或者把有状态的消息根据key放到同一个分区中(消息在落入每个分区前会经过一定的算法,默认情况下时轮询、随机算法,也可以对消息的键进行散列化,再与分区的数量取模运算得到分区编号。对一个不要变的键进行的算法结果永远是同一个值,所以只要分区的数量不变,相同的键的所有消息总是会被写到同一个分区中),到此可以发现,虽然可以实现,但总觉得有些鸡肋(大体实现思路都差不多,还不如创建一个只有一个分区的主题)。
# 2、消费模型
推送模型(push)
拉取模型(pull),kafka采用拉取模型。
为什么kafka采用pull,而不是push?
同一个消费者组内,消费者客户端希望能够对消息精准一次消费
- 如果采用push,以下几点弊端
- 耦合性大、服务端负载大,服务端要做的事情太多了,要负责接收数据保存数据,还要负责控制发送消息。服务端每次还要等待客户端的响应。
- 服务端消息代理控制数据的传输速率,如果消费者会处于超负荷状态(消费者不可控,就不能切合自己能力去处理),那么发送给消费者的消息会越积越多。推送的方式也难以应付不同类型的消费者,因为每个消费者的处理能力各不相同,服务端不好逐一控制
- 每次服务端推送给客户端,都要等客户端的响应,如果客户端宕机了,服务端会有一个重发补救的措施,此时消息的控制权在服务端,服务端消息代理需要维护每条消息在对于每个消费者的状态,这种状态的一致性和性能没法保障,而且也比较复杂,反倒是让消费者自己维护更加合理
- 如果采用pull,控制的权利交给消费者客户端,客户端主动拉取消息,对拉取到的消息做标记,这样消费者可以按照自己的意愿拉取消息。可以实时拉取消息也可以拉取历史消息。也有一个缺点,如果消息量很少,消费者需要不停的轮询。解决这个问题的方案时:允许消费者拉取请求以阻塞式、长轮询的方式等待,直到有新的数据到来。可以设置'指定的字节数量',表示小谢代理在还没有收集足够的数据时,客户端拉取请求就不会立即返回。
- 如果采用push,以下几点弊端
# 3、分布式模型
每个主题的多个分区可以分布式的存储在kafka集群上,每个分区又分为主副本、备份副本,主副本负责读写,副本分区仅仅从主副本同步数据
当主副本故障时,部分副本中的一个副本会被选择为新的主副本。分区副本会均匀的分布在集群服务器上
在代码里写的生产者和消费者实际上在站在kafka的角度来看属于客户端,而集群部署到服务器上的,才是服务端。其源代码在clients包下
分区是消费者线程模型的最小并行单元。
- 一台服务器、一个主题、三个分区、一个消费者
- 三台服务器、一个主题、三个分区、三个消费者(一个消费者对应一个消费者线程,可以加快消费者处理消息的速度,从而提高吞吐量)
综上可以看出,增加服务器节点会提升集群的性能,增加消费者数量提升消息的处理能力
# 3、kafka设计与实现
# 1、文件系统的持久化与数据传输效率
操作系统针对磁盘的读写的优化方案
- 预读:提前讲一个比较平大的磁盘块读入内存
- 后写:将很多小的逻辑写操作合并起来组成一个大的物理写操作
- 操作系统会将驻内存剩余的所有空间都用作磁盘缓存,所有的磁盘读写操作都会经过磁盘缓存,如果是针对磁盘的顺序访问,某些情况下可能要比随机的内存访问要快,甚至可以和网络的速度相差无几
kafka数据持久化优化方案
- 应用程序写入数据到文件系统的过程:在内存中保存尽可能多的数据,并在需要时将这些数据刷新到文件系统
- kafka写入数据到文件系统的过程:数据直接写到持久化日志文件(磁盘缓存),但不进行刷新操作,之后操作系统定期自动刷新到物理磁盘
生产者采用批量发送数据的方式
- 防止请求过多,而是按照收集一定量的消息,批量发送的方式
- 收集xxx字节发送
- 一定时间内发送
- 防止请求过多,而是按照收集一定量的消息,批量发送的方式
读取磁盘文件的数据发送到网络上
- 传统做法:
- 操作系统将数据从磁盘中读取文件到内核空间里的页面缓存(内核缓冲区)
- 应用程序将数据从内核空间读入用户空间的缓冲区
- 应用程序将读取到的数据写回内核空间并放入socket缓冲区
- 操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送出去
- 零拷贝技术(kafka):
- 操作系统将数据从磁盘读取到文件的内核空间里的页面缓存
- 操作系统将内核缓冲区数据和应用程序共享(这样就不需要把内核缓冲区的数据拷贝到用户空间,也不需要用户空间再把数据拷贝到内核空间,避免了两次拷贝,内核态与用户态的交互)。
- 应用程序将数据放入socket缓冲区
- 操作系统将数据从socket缓冲区复制到网卡接口
- 例子:假设有10个不同组的消费者(广播,发布订阅模式),一条消息,那么共需要拷贝多少次?
- 传统做法:(1 + 1 + 1 + 1) * 10 = 40
- 磁盘->磁盘缓冲区 10次
- 磁盘缓冲区 -> 用户空间 10次
- 用户空间 -> 内核空间 10次
- 内核空间 -> 网卡 10次
- 零拷贝技术:1 + 1 * 10 = 11
- 磁盘 -> 磁盘缓冲区 1次(因为共享,下次发送发现磁盘缓冲存在,就不要在从磁盘拷贝了)
- 内核空间 -> 网卡 10次
- 传统做法:(1 + 1 + 1 + 1) * 10 = 40
# 2、生产者与消费者
- 生产者批量发送数据到服务端,消费者也是一次拉取一批消息
# 3、副本机制和容错处理
- 副本在各个服务端节点上对每个主题的各个分区进行复制。当集群中的某个节点出现故障时,访问故障节点的请求会被转移到其他正常节点的副本上。每个分区都有一个主副本和若干个备份副本,备份副本会保持和主副本的数据同步,用来在主副本失效时替换为主副本。
- 生产者在发送消息到服务端时,服务端实际上把消息发给各个分区副本上。可以设置ack应答机制,生产者发送消息确认机制,来保证消息的可靠性。
- ack=1:生产者收到一个主副本响应即可
- ack=0:生产者发送完消息,就结束,不管有没有发送成功
- ack=-1:生产者收到全部的副本响应即可
- 传统做法:
# 4、感悟
# 1、常见问题
- Kafka的主题与分区内部是如何存储的,它有什么特点?
- 一个主题对应多个分区
- 一条主题的消息,会随机或者散列到不同的一个分区(分流,类似于mysql的水平切分)
- 分区类似于一个队列,保证顺序性、存储数据
- 各个分区之前的顺序没有保证
- 与传统的消息系统相比,kafka的消费模型有什么优点?
- kafka采用拉取模式,可以保证消息的不丢失和重复消费问题,可以从任意的位置消费消息,各个消费者可以按照自己的处理能力去消费消息
- Kafka如何实现分布式的数据存储与数据读取?
- 生产者客户端发送消息到服务端时,服务端会更具随机算法或者散列的方式,把消息存储到各个节点分区上,也会保证分区在各个节点上是均衡的。可以设置ack,来控制消息的写入分区副本的情况
- 分区有一个主副本和多个备份副本,当一个主副本无法访问时,备份副本会作为主副本,保证高可用,保证消息的不丢失。主副本可以读写,备份副本仅仅和主副本同步。
- 消费者在读取消息的时候,一个消费者可以读取一个分区也可以读取多个分区。通常情况下,一个消费者读取一个节点下的多个分区的一批数据,然后再做相应的业务处理。如果对一个服务器节点上的每个分区都绑定一个消费者,其实和一个消费者绑定多个分区,在客户端(消息处理)、服务端(消息从磁盘文件读取)上,没啥区别。无非是客户端一次读取的消息变多了,后面客户端使用线程池来写业务的话,负载还是一样的。服务端呢,由于多个分区都在本机,消息从内核态磁盘->内核态socket->网卡->客户端,负载也都一样。只有当分区分布在不同服务器上,这部分负载才会均分。此时如果是一个消费者、三个服务器,每个服务器一个分区,那客户端拉取服务端消息的时候,消费者需要拉取各个服务器的分区消息,这样,客户端的拉取就会变慢,因为客户端只有一个消费者线程,需要轮询从每个节点拉取消息(类似于selector),如果是三个消费者线程,则拉取消息的速度相对会加快(单线程和多线程之间的好处,注意这里强调的拉取消息的快慢,上面提到是拉取消息+消息处理总的速率,因为上面是拉取单个节点,所以速率不取决于消费者线程这块,而这里由于拉取消息变快了,所以总体的性能就上来了,当然客户端还可以分布式部署到不同的服务器上,一个客户端消费者对应一个服务端的多个分区,可想而知,这样更能提升吞吐量)。
- 如何利用操作系统的优化技术来高效地持久化日志文件和加快数据传输效率?
- 数据直接写到磁盘缓冲区上,操作系统定时刷新缓冲区,将数据持久化到磁盘文件上。
- 采用零拷贝技术,加快数据传输效率。
- 用户空间和内核缓存区之间共享数据,内核态把磁盘文件读取到内核态的磁盘缓冲区上(磁盘缓冲区类似于一个缓存,有一定的时效性),磁盘缓冲区的数据可以写到socket,socket再把数据复制到主机A的网卡上,主机A网络传出到主机B的网卡上,主机B解析消息,写到磁盘文件上,之后主机B的应用程序在读取磁盘文件获取数据(netty的理念)。
- Kafka的生产者如何批量地发送消息?
- 生产者客户端会收集一定量的消息再发送给服务端,可以避免频繁的发送消息,减少客户端与服务端的交互,提高性能,策略如下:
- 收集xxx字节的数据后发送给服务端
- 时间间隔后发送给服务端
- 生产者客户端会收集一定量的消息再发送给服务端,可以避免频繁的发送消息,减少客户端与服务端的交互,提高性能,策略如下:
- Kafka的副本机制如何工作,当故障发生时,怎么确保数据不丢失?故障恢复?
- 一个主题、多个分区、每个分区都有一个主副本和多个备份副本,主副本负责读写,备份副本保持与主副本的数据同步,当主副本不可达时,备份副本替换主副本。可以采用ack应答机制,消息一旦写入服务端,主副本和备份副本都处于完全同步状态,所以当备份副本替换主副本时,完全不用担心,因为两者数据都一致。至于重复消费、消息丢失,这由消费者可客户端来控制
# 二、生产者
# 1、概述
- 生产者和消费者客户端与服务端完成一次网络通信的具体步骤:
- 生产者客户端应用程序产生消息
- 客户端连接对象将消息包装到请求中,发送到服务端
- 服务端连接对象负责接收请求,并将消息以文件的形式存储
- 服务端返回响应结果给生产者客户端
- 消费者客户端应用程序消费消息
- 客户端连接对象将消费信息也包装到请求中,发送给服务端
- 服务端从文件存储系统中取出消息
- 服务端返回响应结果给消费者客户端
- 客户端将将响应结果还原成消息,并开始处理消息
# 2、新生产者客户端
# 1、同步和异步发送消息
生产者客户端发送消息,并不是直接发送给服务端,而是先把消息放入队列中,然后由一个消息发送线程从队列中拉取消息,一批量的方式发送消息给服务端。
- kafka记录收集器RecordAccumulator:负责缓存生产者客户端产生的消息
- 发送线程Sender:负责读取记录收集器的批量消息,通过网络发送给服务端
- 选择器Selector:处理网络连接和读写处理
- 网络连接NetworkClient:处理客户端网络请求
同步和异步的原理:客户端发送消息给服务端,实际上是调用了send()方法,方法的返回值是一个future,异步可以接受一个回调函数,同步则调用get()
send方法的处理逻辑
- 序列化消息的key、value,消息必须序列化成二进制流才可在网络中传输
- 为每一条消息选择对应的分区,表示要将消息存储到Kafka集群的哪个节点上,生产者客户端以分区为单位并行发往服务端
- 通知发送线程发送消息
为消息选择分区
- 如果一个消息没有key,则采用轮询的方式,假设期间有的分区不可达,则跳过它,采用才一个可达的分区,当分区再次可达,即可无缝衔接
- 如果一个消息有key,则采用散列取模,使得只要分区数量不变,相同的key的消息永远在同一个分区上
- 客户端为消息选择分区的意义
- 确定了一个分区就等于确定了一个节点,这样就可以把相同分区的消息汇总好,批量发送给一个节点上,节省网络开销,并且由于分区间无状态,故可以采用多线程的方式并行发送到服务端
- 而且和es不同,kafka很少使用协调节点,而是按照算法规则提前算好。比如,在生产者客户端就会确定每条消息的分区,这样就可以减少一次网络开销,试想一下,如果把kafka先把消息随便发送给集群上的某一个节点,再由各个节点去选择分区执行上述逻辑。
客户端记录收集器
按照分区进行分组:消息会按照分区选择,落入不同的分区队列中,每个分区队列还会有许多组批记录(一个批记录的数据结构类似于List,size大小就是可以容纳的字节大小,生产者在x时间内收集x字节的数据就发送)
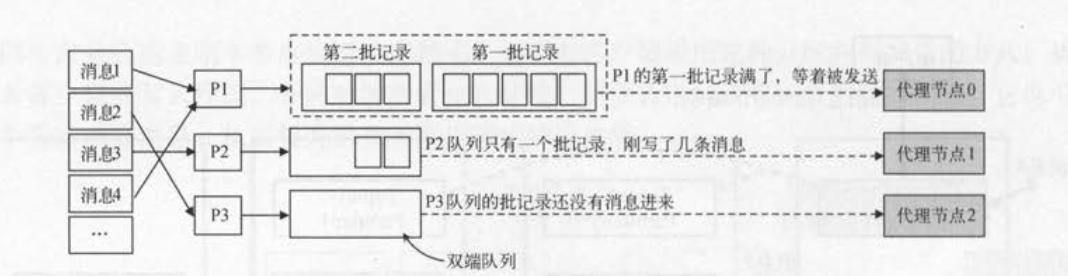
# 2、客户端消息发送线程
从记录收集器获取数据
数据结构:记录收集器按照分区进行分组,并放到batches集合中,客户端发送线程可以使用一个Sender线程迭代各个分区,获取分区对应的主副本节点,在取出分区对应的队列中的批记录就可以发送消息了
- 消息发送线程有两种消息发送方式
- 按照分区直接发送:上面描述的就是按照分区直接发送,单线程或者多线程的方式处理每个分区内的每一个批记录
- 按照分区的目标节点发送:在分区的基础上,在分组,这次根据各个分区的目标节点来分组,然后在迭代发送
#
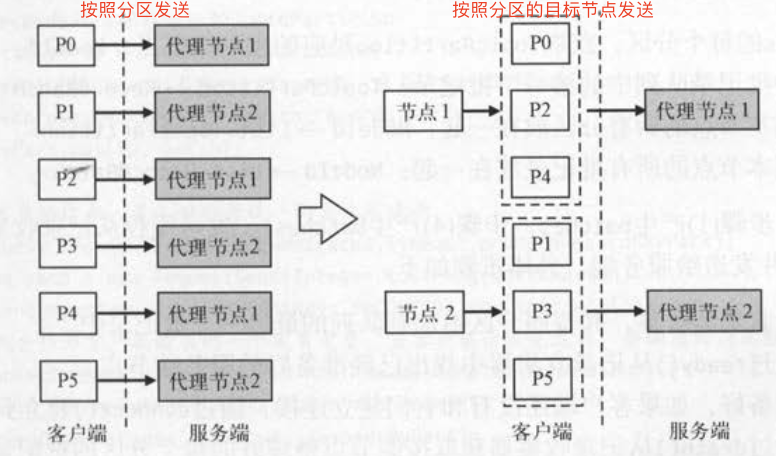
- 消息发送线程有两种消息发送方式
发送线程从记录收集器获取数据,消息追加至分区 -> 读取记录收集器的数据,以便下一步发送至服务端,过程如下:
- 迭代每个分区,获取对应的主副本节点:
NoteId - 获取分区的批记录队列中的第一个批记录:
TopicPartition -> RecordBatch - 将相同的主副本节点的所有分区放在一起:
NoteId -> List<TopicPartition> - 将相同的主副本节点的所有批记录放在一起:
NoteId -> List<RecordBatch>
- 迭代每个分区,获取对应的主副本节点:
创建客户端请求并发送至服务端,过程如下:
- 消息被记录收集器收集,并按照分区追加到队列的最后一个批记录中
- 发送线程从记录收集器中找出已经准备好的服务端节点
- 节点准备好后,客户端与服务端建立连接
- 发送线程从记录收集器获取按照节点整理好的各个分区的批记录
- 发送线程得到每个节点的批记录后,为每个节点创建客户端请求,由客户端网络对象NetworkClient发送至服务端(按照节点并行处理|串行处理)
创建生产者客户端请求
- 客户端发送线程只是获取记录收集器的数据,封装好发送请求,真正执行发送调度逻辑的是客户端网络对象NetworkClient
# 3、客户端网络连接对象(NetworkClient)
概述
- 管理了客户端和服务端之间的网络通信,包括建立连接、发送客户端请求、读取客户端响应,通信方式netty
- 三个重要的方法:
- ready:从记录收集器获取准备完毕的节点,并把准备好的节点汇总好
- send:为每一个节点创建客户端请求,其中包括请求的参数的封装,请求参数就是记录收集器里面的批消息,将请求暂存到节点对应的通道中
- poll:轮询的执行网络请求,包括发送请求给服务端,接收读取服务端响应
准备发送客户端请求
- 客户端send的时候会建立与服务端的连接,如果此时服务端还没有准备好,即还不能连接,则本次请求会在这个处理中被移除掉,确保消息不回发送给还没有准备好的节点;如果服务端准备好了,则建立连接
- send方法建立好连接以后,客户端会把这次封装好的请求加入InFlighRequests列表中,等待后面poll轮询,真正发送至服务端。注意:对于同一个服务端,如果上一个客户端请求还没有发送完成,则不允许发送新的客户端请求。InFlighRequests里面都是需要待发送的请求,当收到服务端响应之后,会把请求从InFlighRequests中移除
客户端轮询并调用回调函数
客户端发送请求不需要响应,一般是同步发送或者是不需要回调处理的异步发送,发送完毕时,就把请求从InFlighRequests队列里移除
开始发送请求->添加客户端请求到队列->发送请求->请求发送成功->从队列中删除发送请求->构造客户端响应
客户端发送请求需要响应,当客户端收到服务端的回调响应时,会调用handleCompletedReceives再进行处理(从队列里移除请求、构造客户端响应)
开始发送请求->添加客户端请求到队列->发送请求->请求发送成功->等待接收响应->接收完整的响应->从队列中删除发送请求->构造客户端响应
客户端请求和客户端响应的关系
- 客户端的连接管理类,把发送线程构造好的客户端请求发送出去,将服务端响应结果构造成客户端响应返回给客户端
- 客户端发送请求、服务端接收请求、服务端返回结果、客户端接收请求
- 发送线程创建的客户端请求对象包括:请求本身 + 回调对象
- 发送线程将客户端请求封装好,交给客户端网络连接对象(NetworkClient),并记录目标节点到客户端请求的映射关系,以便后面节点服务端响应到客户端,客户端根据映射找出当初请求的响应,做处理
- 客户端网络连接对象(NetworkClient)轮询发送请求,将客户端请求发送到对应的服务端节点上
- 服务端处理客户端请求,将响应通过服务端请求通道返回给客户端
- NetworkClient轮询得到响应结果
- 由于客户端请求是发往服务端的各个节点上的,收到的结果也会来自各个节点。服务端发给客户端的响应都会表示它是的从哪里来的,客户端可以根据NetworkaReceive的source查找映射记录信息,得到对应的客户端请求,从中找出客户端响应回调对象
- 调用方法,触发回调函数
- 客户端请求中的回调对象会使用客户端的响应结果,来调用生产者应用程序自定义的回调函数
# 4、选择器处理网络请求
- 客户端连接服务端并建立kafka通道
- kafka通道和网络传输层
- kafka通道上的读写操作
- kafka通道建立简介、读取响应、发送请求,注册连接、读取、写入事件,当选择器在轮询时间听到有对应的事件发生,会获取选择键对应的kafka通道,完成读、写
- 选择器轮询到
写事件- 发送请求时,通过kafka通道的setSend()方法设置要发送的请求对象,并注册写事件
- 客户端轮询到写事件时,会取出kafka通道中的发送请求,并发送给网络通道
- 如果本次写操作没有全部完成,那么由于写事件仍然存在,客户端还会再次轮询到写事件
- 客户端新的轮询会继续发送请求,如果发送完成,则取消写事件,并设置返回结果
- 请求发送完成以后,加入到comleteSends集合中,这个数据会被调用者使用
- 请求已经眼部发送完成,重置send对象为空,下一次新的请求才可以继续正常进行
- 选择器轮询到
读事件- 客户端轮询到读事件,调用kafka通道的读方法,如果网络接收对象不存在,则新建一个
- 客户端读取网络通道的数据,并将数据填充到网络连接对象
- 如果本次读操作没有全部完成,客户端还会再次轮询到读事件
- 客户端新的轮询会继续读取网络通道中的数据,这个数据会被调用者使用
- 读取全部完成,重置网络接收对象为空,下一次新的读取请求才可以继续正常进行
- 选择器轮询
# 3、总结
- Java版本的生产者主要组件
- 记录收集器(RecordAccumulator),将消息按照分区存储,收集消息,提供消息给发送线程
- 发送线程(Sender),针对每个节点都创建一个客户端请求,将消息按照节点分组转交给客户端连接管理类
- 客户端连接管理类(NetworkClient),管理多个节点的客户端请求,驱动连接器工作
- 选择器(Selector),以轮询的方式驱动不同的事件,通知网络通道读写操作
- Kafka网络通道(KafkaChannel),负责请求的发送和响应接收,从原始网络通道中读写字节缓冲区数据
# 4、旧生产者客户端
# 1、新旧生产者区别
- 新生产者nio,旧生产者io
- 新发送消息返回future,且可以自定义回调方法;旧没有提供自定义的客户端回调函数,也可以同步/异步模式
- 旧同步,消息直接交给事件处理器处理;旧异步,消息先缓存到阻塞队列中,再由生产者发送线程定时取出批量消息,交给事件处理器处理
# 2、事件处理器处理客户端发送的消息
- 新版本消息发送流程:将消息保存到记录收集器的不同分区中,每个分区存储批记录的队列,当队列满了,则会触发发送线程,发送线程获取记录收集器的批记录,将记录按照节点分组,针对每个节点创建一个客户端请求
- 旧版本发送消息流程:使用阻塞队列来存储所有消息。只有在发送时才按照节点和分区进行分组,不管某个分区消息有没有满,属于同一个节点的所有分区消息都会一起被发送
- 将消息序列按照节点和分区分组,每个节点都有一个messagePerBrokerMap字典
- 将每个节点包含多个分区的messagePerBrokerMap原始消息,转换成MessageSet
- 调用send()方法,向每个目标节点发送序列化后的消息集MessageSet
- 新版本采用NetworkClient和选择器模式将客户端请求发送到多个服务端节点,旧版本没有选择器,只能在客户端维护每个目标及诶单的网络连接。生产者连接池中保存了BrokerId到一个生产者网络连接对象SyncProducer的映射关系。send()方法会根据目标节点,从连接池获取生产者网络连接对象,将生产者请求发送给目标节点。
# 3、对消息集按照节点和分区进行整理
- 消息分配分区、节点过程
- 获取消息对应主题的分区集合
- 随机、key散列给消息分区
- 获取该条消息上一步分配好的分区,解析出分区的主副本节点
- 构造出这样的数据结构:
消息代理节点编号->分区->消息集
# 4、生产者使用阻塞通道发送请求
- 生产者客户端与各个节点的网络连接
- 新生产者:选择器,连接通道KafkaChannel
- 旧生产者:线程池,连接通道BlokingChannel
# 5、服务端网络连接
# 1、概述
- 完成一次请求处理的具体步骤
- 客户端发送的请求被接收器Acceptor转发给处理器Processor处理
- 处理器将请求放到请求通道R equestChannel的全局请求队列中
- KafkaRequestHandler取出请求通道中的客户端请求
- 调用KafkaApis进行业务逻辑处理
- KafkaApis将响应结果发送给请求通道中与处理器对应的响应队列
- 处理器从对应的响应队列中取出响应结果
- 处理器将响应结果返回给客户端,客户端请求处理完毕
# 2、服务端使用接收器接收客户端的连接
- 服务端采用Nio的方式,会先启动一个接收器线程Acceptor和多个处理器Processor。
- NIO服务用一个接收器线程专门负责接收所有的客户端连接请求,对于每个请求的处理则交给处理器处理(这个处理器类似于处理线程池)。这是一种Reactor模式。
- 这样设计的意义?
- 如果服务端为每个客户端都维护一个连接,很耗资源性能;
- 这种通过一个接收线程来处理客户端的连接请求,并使用一个选择器轮询的的方式,即可以实现需求也可以避免多线程间的上下文切换
- 客户端建立连接到服务端接受连接的步骤
- 服务端的ServerSocketChannel向选择器注册OP_ACCEPT事件
- 客户端向选择器注册OP_CONNENT事件,并调用SocketChannel.connent()连接服务端
- 服务端的选择器监听到客户端的连接事件,接受客户端的连接
- 服务端使用ServerSocketChannel.accept()创建和客户端通信的SocketChannel
# 3、处理器使用选择器的轮询处理网络请求
- 完整的请求和响应过程
- 客户端完成请求的发送,服务端轮询到客户端发送的请求
- 服务端接收完客户端发送的请求,进行业务处理,并准备好响应结果发送给客户端
- 服务端完成响应的发送,客户端轮询到服务端发送的响应
- 客户端接收完服务端发送的响应
# 4、请求通道的请求队列和响应队列
- 客户端->服务端请求处理过程:发送请求->接收请求->发送响应->接收响应
- 处理器收到客户端请求后,将请求放入请求队列requestQueue
- 请求处理线程冲队列中获取请求,并交给KafkaApis处理
- KafkaApis处理完,将响应结果放入响应队列responseQueue
- 处理器从响应队列中获取响应结果发送给客户端
# 5、Kafka请求处理线程
- 请求处理线程池,请求处理器处理请求(维护请求队列和响应队列),请求处理线程池负责多线程的调度,请求处理线程共同消费同一个请求通道中的所有客户端请求,每个请求处理线程获取到请求后,都交给统一的KafkaApis处理,注意:一个KafkaServer有多个请求处理线程,但只有一个KafkaApis
- 一个接收器(单个线程),多个处理器。接收器接收请求,创建和客户端通信的SocketChannel,将其交给处理器,一个处理器多个通道,一个通道对应一个客户端连接,处理器使用Selector轮询通道数据,一个通道传给请求处理线程和KafkaApis,处理器将客户端请求放到全局的请求队列中,供请求处理线程获取,请求吹线程将请求转发给KafkaApis处理,最后KafkaApis将处理完成的响应结果放到响应队列中,供处理器获取后发送给客户端。
- 一个接收器线程Acceptor、多个处理器Processor;一个请求通道RequestChannel、一个请求队列requestQueue、多个响应队列responseQueue、一个请求处理线程连接池KafkaRequestHandlePool、多个请求处理线程KafkaRequestHandle、一个服务端请求入口KafkaApis
# 6、服务端的请求处理入口
# 5、小结
# 6、感悟
# 三、消费者高级API、低级API
# 1、概述
- 使用消费组实现消息队列的两种模式
- 发布订阅模式(广播),多个消费组、每组多个消费者。消息共享给各个组,组内根据各消费者分配的分区,进行消费,一条消息只能被组内一个消费者消费
- 队列模式(单播、点对点),只有一个消费组、多个消费者,组内根据各消费者指定的分区,进行消费,一条消息只能被组内一个消费者消费
- 消费组再平衡实现故障容错
- 何时会触发再平衡?
- 消费组内,消费者加入或退出,导致组内成员列表发生便活
- 订阅的主题分区发送变化
- 为所有消费者重新分配分区,消费者之间如何确保各自消费信息的平滑过渡?消费者再平衡故障容错。
- P1分配给C1,重平衡之后,P1分配给了C2,再平衡前P1保存了自己的消费进度(组级别),再平衡后C2直接从进度位置继续读取P1
- 何时会触发再平衡?
- 消费者保存消费进度
- 分区保存自己的消费进度,组级别
- 消费进度怎么保存的?如何在组内共享?
- 保存在外部存储系统中,ZK或Kafka内部主题_consumer_offsets
- 消费者消费消息时,会定时将分区最新的消费进度保存下来
- 分区分配给消费者
- 分区分配给消费者场景
- 线程数>分区数,部分线程多余
- 线程数=分区数,一线程消费一分区
- 线程数<分区数,有些线程消费多个分区
- 分区分配给消费者场景
- 消费者与ZK关系
- ZK存储哪些东西?
- ZK保存Kafka内部元数据
- 记录消费组成员列表
- 记录分区消费进度
- 消费组管理消费者,消费组从ZK获取可用的分区和存活的消费者,分区分配给消费者
- ZK存储哪些东西?
# 2、消费者启动和初始化
# 1、概述
- 消费者连接器
- 连接ZK集群
- 获取分配的分区
- 创建每个主题对应的消息流KafkaStream(消息流从服务端分区读取消息,并将其存入阻塞队列中)
- 迭代消息流,读取每条消息
- 消费者客户端通过消费者连接器读取消息步骤
- 消费者的配置信息指定订阅的主题和主题对应的线程数,每个线程对应一个消息流
- Consumer对象通过配置文件创建基于ZK的消费者连接器
- 消费者连接器根据主题和线程数创建多个消息流
- 在每个消息流通过循环消费者迭代器ConsumerIterator读取消息
# 2、创建并初始化消费者连接器
- 消费者连接器接口,方法
- createMessageStream(),创建消息流并返回给客户端应用程序,读取的消息存入队列
- commitOffset(),提交分区偏移量元数据到ZK或Kafka内部主题中
- Listeners,注册主题分区的更新、会话超时、消费者成员变化事件,触发再平衡
- zkUtils,从ZK中获取主题、分区、消费者列表,为再平衡时的分区分配提供策略
- topicRegistry,给消费者分配的分区,主题->分区->分区信息
- Fetcher,消费者拉取线程的管理类,拉取线程会向服务端拉取分区的信息
- TopicThreadIdAndQueue,消费者订阅的主题和线程数,每个线程对应一个队列
- offsetsChannel,偏移量存储为Kafka内部主题时,需要和管理消费组的协调者通信
- 创建消费者连接器时,需要执行以下初始化方法
- 确保连接上ZK,因为消费者要和ZK通信,包括保存消费进度或者读取分区信息等
- 创建消费者拉取管理器ConsumerFetcherManager,管理所有消费者拉取线程
- 确保连接上偏移量管理器OffsetManager,消费者保存消费进度到内部主题时和它通信交互
- 调度定时提交偏移量到ZK或Kafka内部主题的线程
# 3、消费者客户端线程模型
- 消费者连接器createMessageStreams()方法执行逻辑
- 根据客户端传入的topicCountMap构造对应的队列和消息流,消息流引用了队列
- 在ZK的消费组副节点喜爱注册消费者自己诶单
- 执行初始化工作,触发再平衡,为消费者分配分区,拉取线程会拉取消息放入队列中
- 返回消息流列表,队列中有数据时,
- 分布
- 一个主题、多个分区
- 多个分区分配给若干个消费者,一个消费者有多个消费者线程,一个消费者线程至少被分配一个分区
- 一个消费者线程、一个队列、一个消息流
# 4、重新初始化消费者
- 初始化时,消费者加入到消费组里,此时会触发再平衡,即给每个消费者分配分区
- 常见的监听器,监听是否触发再平衡
- 当新的会话建立或者会话超时需要重新注册消费者(会话超时事件)
- 当主题的分区数量变化(主题分区变化事件)
- 当消费组成员变化(消费组子节点变化事件)
# 3、消费者在平衡操作
# 1、概述
- 再平衡操作步骤
- 关闭数据拉取线程,清空队列和消息流,提交偏移量
- 释放分区的所有权,删除ZK中分区和消费者的所有者关系
- 将所有分区重新分配给每个消费者,每个消费者都会分到不同的分区
- 将分区对应的消费者所有者关系写入ZK,记录分区的所有权信息
- 重新启动消费者的拉取线程管理器,管理每个分区的拉取线程
- 拉取线程和分区所有权的关闭和开启顺序为:
- 停止拉取线程
- 释放分区所有权,根据分区号删除ZK信息
- 添加分区所有权,根据消费者线程号+分区号,保存至ZK
- 启动拉取线程
# 2、分区的所有权
# 3、为消费者分配分区
- 步骤
- 构造消费者的分配上下文,得到订阅主题的分区和所有的消费者线程信息
- 分区分配算法计算每个消费者的分区和消费者线程的映射关系
- 从不走2的全局结果中获取属于当前消费者的分区和消费者线程
- 读取当前消费者拥有的分区再ZK中的最新消费进度,即它所拥有的分区的偏移量
- 构造PartitionTopicInfo,加入到表示消费者的主题注册信息的topicRegistry中
- 更新topicRegistry,后面的拉取线程会使用该数据结构
# 4、创建分区信息对象
- 分区表示拉取线程的‘目标’;队列作为消息的‘存储’截止;偏移量作为拉取‘状态’。消费者的拉取线程会以最新的状态拉取目标的数据填充到存储队列中。
- 拉取偏移量fetchedOffset表示从哪里开始拉取;消费偏移量consumedOffset表示消费到了哪里
- 步骤
- 连接器根据订阅信息生成队列和消息流的映射,并且队列也会传给消息流
- 为消费者分配分区时,会从ZK中读取分区偏移量(关闭时保存的consumedOffset)
- 根据偏移量创建分区信息,队列也会传给分区信息对象
- 分区信息被用于消费者的拉取线程
- 拉取线程从服务端的分区拉取信息
- 消费者拉取到消息后,会将最新的拉取偏移量更新到ZK
- 拉取线程将拉取到的消息填充到队列里
- 消息流可以从队列里获取消息
- 应用程序从消息流里迭代获取消息
# 5、关闭和更新拉取线程管理器
- 关闭和更新拉取线程管理器前,需要将拉取线程填充的那些队列清空,更新偏移量到ZK
# 6、分区信息对象的偏移量
- 分区信息对象的偏移量再拉取线程中启动的作用,步骤
- 关闭拉取线程时提交consumerOffset偏移量到ZK
- 重新启动拉取线程时读取ZK中的偏移量
- 将ZK的偏移量作为刚开始的fetchedOffset
- 客户端读取到消息后会更新consumedOffset
- 在这之后每次拉取使用的fetchedOffset都来自于最新的consumedOffset
- 客户端进程定时提交偏移量,即consumedOffset写到ZK中
- 消费者客户端使用消费者连接器的主要工作,步骤
- 创建队列(保存消费这些拉取到的消息)和消息流(读取消息)
- 注册各种时间的监听器,当事件发生时,消费组所有消费者成员都在再平衡
- 再平衡会为消费者重新分配分区,并构造分区信息加入topicRegistry
- 拉取线程获取topicRegistry分配给消费者的所有分区信息开始工作
# 4、消费者拉取数据
# 1、拉取线程管理器
- 管理了当前消费者的所有拉取线程,拉取线程从服务端分区拉取消息
- 选择有主副本的分区
- 拉取线程管理器,找出已经有主副本的分区,若找到则分配给拉取线程
- 创建拉取线程
- 让一个拉取线程管理一个消息代理节点上的多个分区
- 拉取线程的拉取状态
- 拉取管理器的LeaderFinderThread后台线程工作
- 后台线程调用抽象拉取管理器的addFetcherForPartitions()方法
- addFetcherForPartitions()方法调用createFetcherThread()抽象方法
- 消费者拉取管理器的createFetcherThread()创建具体的消费者拉取线程
- 消费者拉取管理器调用抽象拉取线程的addPartitions()将分区添加到步骤3的拉取线程
- 拉取管理器的LeaderFinderThread后台线程工作
# 2、抽象拉取线程
- 构建拉取情趣
- 一个拉取线程要处理多个分区的拉取请求,抽象拉取线程要对partitionMap的操作加锁
- 处理拉取请求
- 消费者和备份副本的拉取工作都一样,拉取线程向服务端拉取消息的步骤
- buildFetchRequest(partitionMap)根据partitionMap构建拉取请求
- fetch(fetchRequest)根据拉取请求向目标节点拉取消息,并返回响应结果
- processPartitionData(partitionData)处理拉取到的分区结果数据
- 消费者和备份副本的拉取工作都一样,拉取线程向服务端拉取消息的步骤
- 第一次拉取状态从ZK读,然后计算放入本地缓存partitionMap,后面都从这里读取,客户端会定时保存消费状态。对于消费者客户端,通过开启autoCommit开关,定时提交分区偏移量到ZK中;对于备份副本,会将偏移量写到本地的检查点文件中
# 3、消费者拉取线程
- 分区信息的队列保存拉取的消息
- 拉取出现错误的处理方式
- 拉取线程拉取错误时(主副本变化、分区变化等),会停止拉取,重新分配。从分配分区给消费者,到拉取线程拉取消息返回给消费者的额具体步骤
- 再平衡操作将分区分配给消费者,读取ZK的偏移量作为分区信息的拉取位置
- 分区信息的队列用来存储结果数据,拉取偏移量作为拉取线程初始的拉取位置
- 拉取线程拉取分区的数据,初始时从拉取偏移量开始拉取消息
- partitionMap表示分区的最新拉取状态,每次拉取数据后都要更新拉取状态
- 拉取线程创建拉取请求,并通过SimpleConsumer发送请求和接收响应结果
- 拉取线程拉取到分区消息后,将分区数据的消息集填充到分区信息对象的队列
- 创建消费者连接对象时,会创建队列和消息流,一个对联关联了一个消息流
- 消费者客户端从消息流中迭代读取结果数据,实际上就是从队列中拉取消息
- 正等待被消费:消息流中的数据即为正等待被消费的数据,只有客户端真正消费了该数据,才表示消息已经到达客户端
- 拉取线程拉取错误时(主副本变化、分区变化等),会停止拉取,重新分配。从分配分区给消费者,到拉取线程拉取消息返回给消费者的额具体步骤
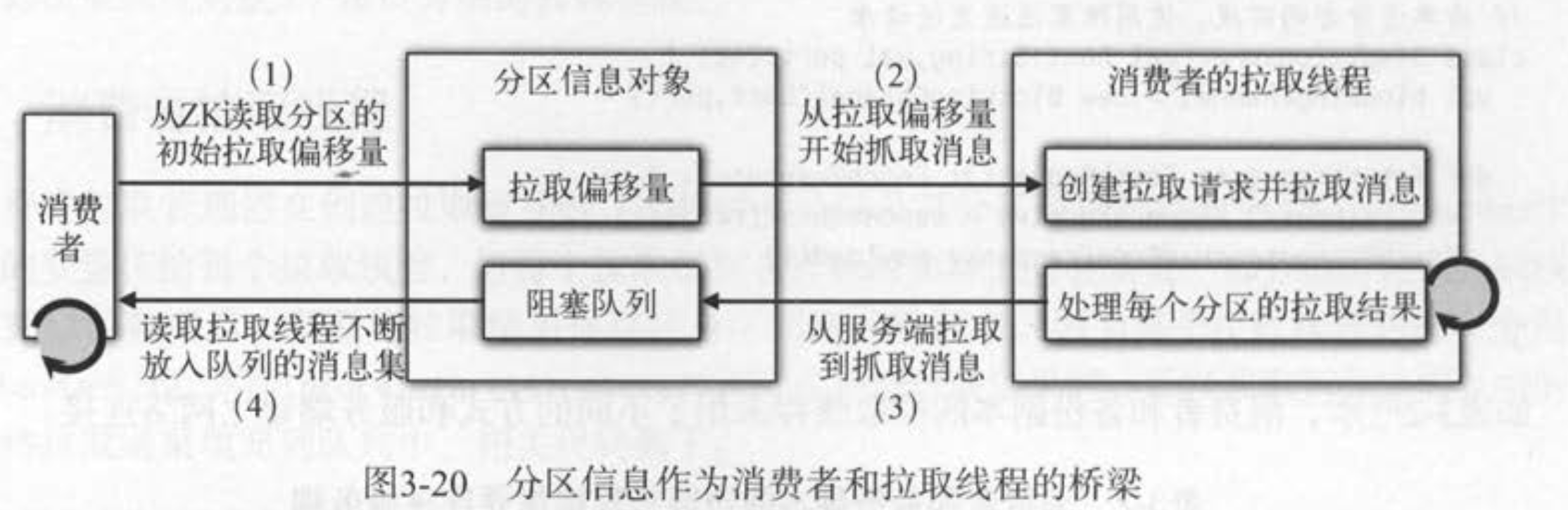
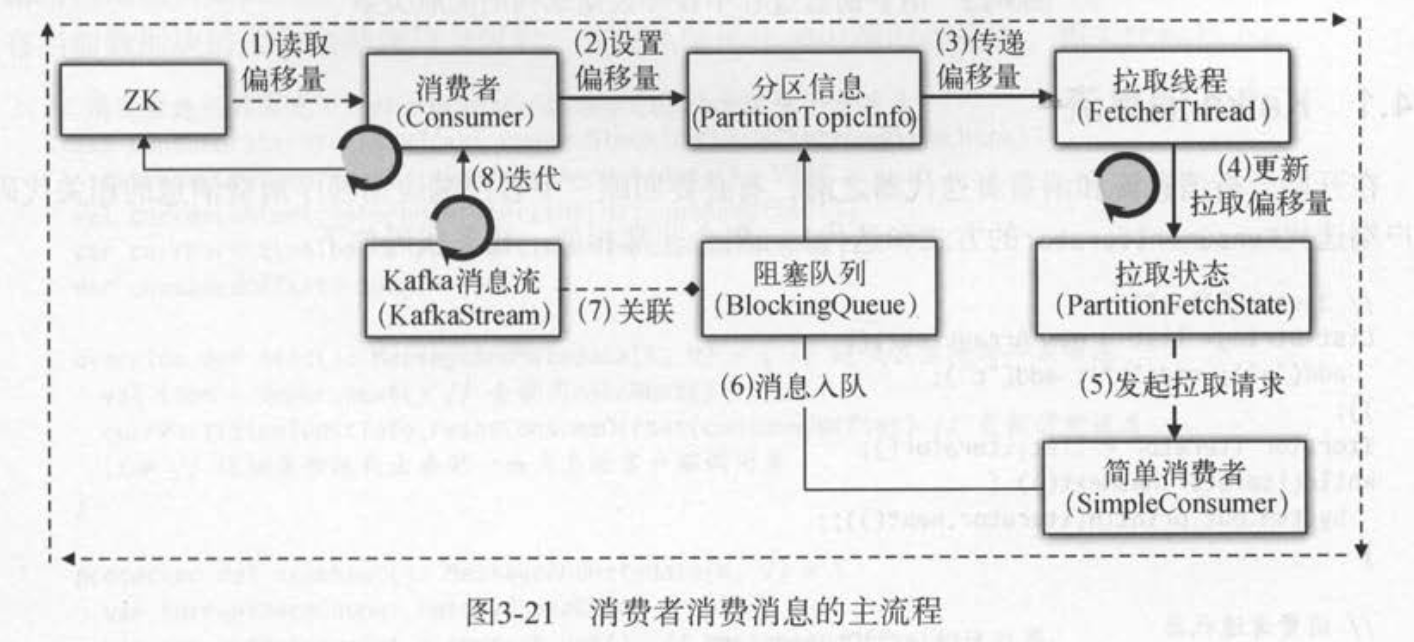
# 5、消费者消费消息
# 1、kafka消息流
- 在向服务端拉取数据时,一次是拉取多个分区的消息(消息集),消费者客户端迭代消息流,实际上是迭代每个数据块中消息集的每条消息
# 2、消费者迭代消费消息
- 队列的数据结构类似于这样:List<List<消息>> 队列里面包着多个消息集
- 消费者拉取线程拉取消息后会更新拉取状态;客户端消费线程获取消息处理后也要更新相关的消费状态(这个消费线程实际上就是一个迭代器,不停的从消息流中迭代消息)
- 拉取状态对应分区信息对象的拉取偏移量fetchedOffset,表示消费者已经拉取的分区位置;消费状态对应了消费偏移量consumedOffset,表示消费者已经消费完成的偏移量。具体步骤:
- 消费者的拉取线程从服务端拉取分区的消息
- 拉取到分区消息后,就更新分区信息对象的拉取偏移量(本地更新)
- 将分区数据的消息集封装成数据块
- 客户端循环迭代数据块的消息集
- 消费完一条消息后,就更新分区信息对象的消费偏移量
- 消息流中的每一条消息返回给消费者客户端应用程序
# 6、消费者提交分区偏移量
# 1、概述
- 分区信息的拉取偏移量初始时从ZK读取,然后再拉取消息后本地更新维护,消费偏移量初始时从ZK读取,然后再消费消息后更新(现在本地维护后定时更新到ZK)
# 2、提交偏移量到ZK
- 提交的分区偏移量以‘消费组’为级别,避免,同一个消费组内消息不回重复消费
# 3、提交偏移量到内部主题
同一个消费组的偏移量提交到同一个服务端节点上,这个节点负责管理一个消费组内所有消费者的所有分区的偏移量,叫做偏移量管理器OffsetManager
客户端需要确定服务端机节点的几个场景
生产者发送消息时,直接在客户端决定消息要发送给那个分区,这一步不向服务端发送请求
消费者拉取管理器的LeaderFinderThread线程向服务端发送主题元数据请求,获取包含了主副本等信息的所有分区元数据,消费者拉取线程才能确定要连接那些服务端节点
提交偏移量有点像生产者发送消息,都是些数据,但也需要和消费者的LeaderFinderThread一样,向服务端发起请求,获取分区的主副本作为偏移量管理器,确定提交到节点
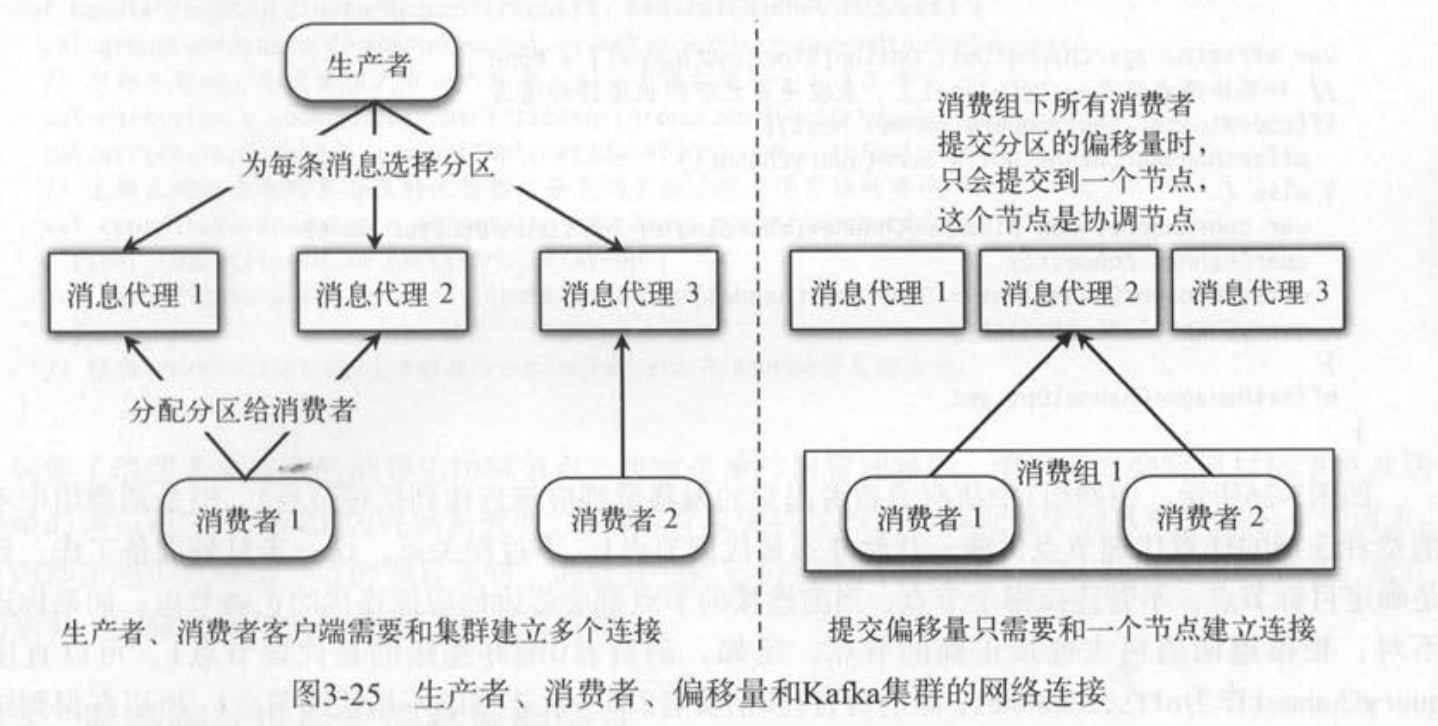
# 4、连接偏移量管理器
- 消费者需要向服务端任意一个节点发送‘消费组的协调者请求’,来获取消费组对应的协调节点,即偏移量管理器OffsetManager节点。在服务端,选择消费组对应的内部主题的分区的主副本节点,然后直接返回这个协调节点给客户端。(客户端请求任意服务端,服务端返回一个协调节点,同一个组的协调节点不变)
- 各消费组确定协调节点之后,即可连接节点,发送偏移量的读写请求
# 5、服务端处理提交偏移量的请求
- 过程:将消息追加到本地日志文件,然后会把分区和对应的偏移量保存在协调节点的缓存中,目的是再平衡后如果其他消费者需要读取分区的偏移量,可以直接读缓存,而不是读文件。先写日志,写日志成功后再回更新缓存。
- 消费者发送提交偏移量和获取偏移量都会被服务端的KafkaApis处理,服务端处理这两个请求的步骤如下:
- KafkaApis将提交偏移量请求的处理交给消费者的协调者GroupCoordinator
- 消费组的协调者再交给消费组的元数据管理类GroupMetadataManager去处理
- 延迟的存储对象DelayedStore会调用副本管理器的appendMessage()存储消息
- 副本管理器将消息追加到低层文件系统的文件日志中,这样分区的偏移量就存储到服务端上了
- 分区和对应的偏移量会在消息存储成功后,被缓存至服务端消费组元数据管理类
- 服务端处理客户端的获取分区偏移量请求,首先从缓存获取
- 缓存没命中就从文件里取
# 6、缓存分区的偏移量
- 偏移量消息缓存数据结构:键:消费组、主题、分区 组成;值:分区的偏移量
- 分区方式只由消费组决定
# 7、消费者低级API示例
# 1、概述
# 2、消息消费主流程
# 3、找出分区的主副本
- 客户端向任意节点发送主题元数据请求,因为每个经济诶单都保存了集群所有的主题元数据,所以数据都是一致的。主题元数据包含了多个分区的元数据,消费者在创建时会指定消费特定的分区,所以需要从中找出对应的分区元数据
# 4、获取分区的读取偏移量
- 一个分区有多个片段文件S egment,每个片段文件都包含全局有序的片段基准偏移量se gmentBaseOffset
# 5、发送拉取请求并消费消息
- 高级API,从服务端拉取一次偏移量,后面会在本地维护偏移量缓存pa rtitionMap,收到一批完整的消息后在更新到服务端。获取到消息后放入队列
- 低级API从服务端拉取偏移量,更新到服务端,以此往复。获取到消息后直接消费
# 8、小结
# 1、消费者线程模型
# 2、再平衡和分区分配
# 四、新消费者
# 1、新消费者客户端
# 2、消费者的网络客户端轮询
# 3、心跳任务
# 4、消费者提交偏移量
# 5、小结
# 6、感悟
需求疑问
maap接入号怎么分配的?是给一个号码段,这个号码段是线上申请的还是maap线下给的。号码段的意义?只是预分配接入号,我们或者maap后面可以根据号码段前缀禁用子接入号吗?我的理解,一个地市一个号码段,地市发展的商户,都在这个号码段的子集。
计费,怎么个流程?包月、计件。套餐用完,计件还是继续购买套餐?
计件怎么扣费?计次后付费还是实时预付费?购买套餐,累加次数还是套餐升级?套餐的费用,怎么计费?
SP和电信maap。电信maap只给号百和号百的商户开放(用不用得看商户怎么选择了)?三网SP给各个地市、代理商、商户开放?
实现疑问
项目分层(待确定)
— 公众平台
— 服务提供
— Provider模块
— 能力平台
— 鉴权模块
— Api模块
— Provider模块
— 服务提供
— 核心模块
— 系统管理
— 注册中心
— 配置中心
— 网关流控
— 公共模块
— 工具类 — 常量类
SP分配给号百的10位自由发展的商户(接入号段)
- 分配的号段,后续还需要到SP开通,线上、线下?
- SP可能封号段,封多少位?
- 一方的SP是否可以将开户信息同步给其他方?
chatbot名称唯一。SP后面只需要一个接入号,可以在其他家共享吗?需要在每个SP单独维护?
消息资费防止各个地市打价格战?
- 套餐是否需要统一资费
- 是否需要上下限
待确认:预付费包月、后付费包月|合同期,两种都可以叠加、话单
余额不足,停止发送策略?待确认:任务、工单 执行时,计费判断
- 欠费,任务工单是否需要加锁?只在任务时判断一次,要么全发,要么全不发
商户注册流程尽量简化
人工客服,是否可以弹H5页面,绕过maap平台,客服与终端交互
套餐是否需要包含交互场景?交互场景的消息,怎么收费、套餐怎么划分?交互场景收费方式?电话-定制
商户注册申请接入号是否需要付费
能力平台和公众平台怎么区分?能力平台的门槛在哪?
- 消息内容校验是否需要需要收费?(我们调百度审核,百度也是要收费的)
能力平台、公众平台 商户 权限划分?
- 能力平台智能调接口
- 两平台不共用
任务工单消息用户账户 状态
后端->前端 推送消息,任务执行情况;能力平台->客户端
发送成功再扣费,消息未接收到也不收钱,看maap消息状态报告
- 先扣,后面根据状态再补偿
预付费扣费,策略
- 发送成功的就扣费,48小时内根据发送失败的,再退费
grafana、logservice
1、linux上自带的kafka生产者和消费者命令有时成功有时不成功。(初步猜测是网络问题)
2、kafka消费组的groupid设置,有的设置成功,有的设置失败导致消费者找不到协调者,之后在broker上查不到该groupid。
3、在springboot中,kafka生产者功能实现使用spring-kafka提供的KafkaTemplate,并设置事务id的前缀为tran-。 项目启动时会生成多个生产者,且产生错误: ERROR o.s.kafka.transaction.KafkaTransactionManager - Commit exception overridden by rollback exception org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer's transaction has been expired by the broker. 2020-08-12 18:25:04.942 [http-nio-8087-exec-4] WARN o.s.kafka.core.DefaultKafkaProducerFactory
Error during transactional operation; producer removed from cache; possible cause: broker restarted during transaction: CloseSafeProducer [delegate=org.apache.kafka.clients.producer.KafkaProducer@1cdcb607, txId=tran-0] 使用kafka client实例化生产者对象,目前可避免这样的错误
4、kafka精准一次消费的实现方案问题
用1.1以上版本
0.10 c++客户端
消费者耗尽服务器资源,解决方式:kafka配额调优,原因:kafak消费速率与主机性能不匹配
避免broke文件句柄被耗光
运维关注:network请求空闲率
9主机 40分区 7000/s 80MB 主机配置40核、256G
内存使用率30%标准,那边建议不超过60%
2K 50000 100 000
40线程读取
9个服务器消费
业务数据存文件系统,流数据通过kafka,存es上